
FUSE s3 Mapserver
2018-07-09
Mapserver is a pretty convenient way to host WMS services in a lightweight, easy-to-implement manner. One can just point the Mapserver instance at a directory and it will host all the 'mapfiles' (.map extension) residing in there. Super easy, but could it be easier? When the Mapserver instance is running on a separate server, like in AWS, then one would have to SSH onto the machine to create new mapfiles or at least SCP the new ones onto it. Why not setup the instance on an EC2 with an s3 bucket mounted as the mapfile directory? Then mapfiles can be managed within the s3 bucket! Much easier to access - especially for less technical staff.
Backstory
This post is the result of handling the Mapserver side of my COG processing pipeline project: Just Another COG in the Machine. The purpose of that project was to go the extra yard and setup the described above but with Mapfiles managed in s3 by Lambda functions, not directly by staff.
In this post I'm going to lay out the step-by-step process and commands I used to create a dockerized, Mapserver instance which hosts WMS Services from mapfiles residing and managed in an s3 bucket. I established this setup by working with a one-off, micro ec2 instance for testing (and could be followed to setup a stand alone ec2 if you like managing the dockers yourself) but these steps are aimed at running the Mapserver in AWS ECS (elastic container service).
The reason I'm setting this up in ECS is very simple: ECS is awesome. ECS will manage your dockers for you which ensures they stay running and are performing. The problem to always consider is that with this service, docker instances and their machine instances may come and go. That means any machine provisioning must be built into the AMI so that if an EC2 in the ECS Cluster is turned off or replaced, the new one is already set to go. For our Mapserver, we will be running it in a container dependent upon a volume on it's host machine that is a special mounted s3 directory. This means that the majority of this project is creating an AMI (amazon machine image) properly provisioned with this drive and associated permissions so that we can deploy an ECS cluster utilizing it to host the container service that is the Mapserver.
One crucially awesome aspect of Mapserver, which is also the key that makes this setup possible, is that with every client request to Mapserver is a new, fresh pull from the mapfile. This means that one can edit and update mapfiles and Mapserver doesn't need any new deployment, refreshing, or reconfiguring to make the changes instantly available. Add a new mapfile or edit an existing one and it is immediately available with the very next request. We couldn't deploy Mapserver as a Amazon managed docker otherwise because every time a new mapfile appeared or the docker turned off, a manual effort would be required to get it all going again... And we want less work, not more.
Steps to Create the Mapserver
0 - Prerequisites
- s3 Bucket for the mapfiles (and COGs in our case). For the instructions below, we will assume it is named "mapserver-bucket". Mapfiles in s3 need to have the proper headers with the 'mode', 'mtime', 'uid', and 'gid' so dig into step # 27 of the custom AMI below for details.
- AWS IAM User with an Access Key ID and Secret Access Key. Set the keys aside as we will need them to provision the ECS Optimized EC2 AMI. (If serving WMS Services pointed at s3 like in this project, you can use these keys in the mapfiles to access the COGS)
- Create and apply an IAM Permission Policy to the user with read and write permissions to the s3 bucket
- Local install of Docker
- Local install and configuration of AWS CLI. You'll need AWS permissions to EC2, ECS, and s3 at least.
- Background knowledge of cloud security, cloud networking, and linking together AWS services appropriately. I'll give structural overviews and some decent details but won't go into command specifics of many of this.
- Terraform is suggested for Act III.
I - Create a Custom AMI
-
Get the latest and greatest 'ECS optimized' AMI as the base to provision for our purposes. On the day of writing this, the code for this AMI is
ami-5253c32d.
I haven't found an easier way to get this aside from going to the AWS console, click ECS, choose to 'Create Cluster', and see it listed in the form. Searching the community AMI library for 'ECS' reveals lists of ECS images and doesn't descipher which is the latest so this is simply how I find it right quick. - Use the latest ECS AMI code to create a free t2.micro EC2 instance. Setup security so that you can SSH onto the instance and so that it has web access for downloading packages. We will only need this machine running for a few minutes as we provision it and create a custom AMI. Then we will terminate it.
- SSH onto your new instance. Connection information is found by right clicking the instance and choosing 'Connect' in the EC2 Dashboard instance list.
-
This is where the fun begins. We will be following these basic instructions to install FUSE s3fs and mount our bucket.
sudo yum update allto ensure the OS is up to date -
sudo yum install automake fuse fuse-devel gcc-c++ git libcurl-devel libxml2-devel make openssl-develto install FUSE -
git clone https://github.com/s3fs-fuse/s3fs-fuse.gitto clone the FUSE s3fs project -
cd s3fs-fuseto move into the project folder for installation -
./autogen.shfor compilation -
./configure --prefix=/usr --with-opensslfor compilation -
makefor compilation -
sudo make installfor installation -
which s3fsshould print '/usr/bin/s3fs' to prove the installation was successful -
cd ..to back out into the ec2-user home directory ('/home/ec2-user') -
touch .passwd-s3fsto create the s3fs credential configuration file -
vi .passwd-s3fsto open the file for editing -
With the file open for editing in vi, hit the
ikey to start 'insert' mode.
Then enter the user Access Key ID and Secret Access Key from the prerequisites above, separated by a colon, on a single line.
Like this:<-- access key id -->:<-- secret access key -->
Then save and close the file by clicking theESCkey, then typing:wq!, and finally hittingEnter.
I know what you're thinking right now -- "instructions include how to close vi editor?!?!?!". Yup, you're welcome. ;) -
cat .passwd-s3fsto print the file contents and ensure yourself it saved properly -
chmod 600 ./.passwd-s3fsto apply necessary permissions to the file -
cat /etc/fuse.confto print the file contents for the FUSE configuration. we will be editing this -
sudo vi /etc/fuse.confto open the file for editing -
With the file open for editing in vi, hit the
ikey to start 'insert' mode.
Then arrow down and delete the comment hash and space in front of 'user_allow_other'.
The file contents should look like this:# mount_max = 1000 user_allow_other
Then save and close the file by clicking theESCkey, then typing:wq!, and finally hittingEnter. -
cat /etc/fuse.confto print the file contents and ensure yourself it saved properly -
mkdir bucketto make a directory which we will use to mount the s3 bucket. I'm calling it 'bucket' for this instructional but you can call it whatever you'd like -
s3fs mapserver-bucket -o multireq_max=5 -o allow_other ./bucketto mount the bucket to our directory. If you feel desire to unmount it, the command would besudo umount ./bucket -
sudo vi /etc/rc.localto open the rc file. We will be adding an entry for automatically mounting the directory on boot. -
With the file open for editing in vi, hit the
ikey to start 'insert' mode.
Then arrow down and add a line for running the s3fs mounting command with hard paths to the binary and directory to mount. The command should be run by user ec2-user. You identified the binary path earlier with the commandwhich s3fs.
The added line should look like this:sudo runuser -l ec2-user -c '/usr/bin/s3fs mapserver-bucket -o multireq_max=5 -o allow_other /home/ec2-user/bucket'
Then save and close the file by clicking theESCkey, then typing:wq!, and finally hittingEnter. -
Very Important: Mapfiles in s3 need to have the proper headers with the 'mode', 'mtime', 'uid', and 'gid'. This is so that they have the proper ownership and permissions as file metadata through s3fs. If uploading Mapfiles manually through the console, you can edit add these headers in the object's 'Properties' -> 'Metadata'. If uploading via an SDK, you can add these headers as ExtraArgs when doing the file upload. The 'uid' and 'gid' need to be that of the user running Mapserver.
id -u ec2-user&id -g ec2-userto get 'ec2-user' user's UID and GID. It seems standard and reliable to me that Amazon OS default user 'ec2-user' is UID and GID500.
Specifically, these headers should work for the mapfiles:'mode':'33204' 'uid':'500' 'gid':'500' 'mtime':'1528814551' -
Under the exact same guise as the previous step, if the mapfiles will be in any 'sub-directories' of the bucket rather than the root, those directories need to have 'ec2-user' filesystem ownership and permissions for Mapserver to access them. A simple
mkdiras 'ec2-user' while SSH'd in accomplishes this. Just note that if you upload mapfiles to any s3 'folders' which were created in the AWS Console, the owner will be root and mapserver will not have access. -
exitto end the SSH session. - Now let's save the image. Open up the AWS Console, navigate to the EC2 Dashboard, right click our temporary micro EC2, choose 'Image' -> 'Create Image'. Fill in an 'Image name' and 'Image description'. Click the blue button and chill out while the image is saved. View if it's complete by choosing 'AMIs' under 'IMAGES' on the sidebar.
II - Create a Custom Mapserver Docker Image
You can manually spin up the dockerized Mapserver instance on the AWS EC2 with just a few commands but we will have to go further to cut down on the steps of the manual process in preparation for ECS. We will use the image "camptocamp/mapserver:7.4" from DockerHub. For peace of mind, I'll list the steps for the manual spin-up here:
-
sshonto the EC2 -
sudo docker run --detach -v /home/ec2-user/bucket:/mapfiles:ro --publish 8080:80 --name mapserver camptocamp/mapserver:7.4to spin up the docker container. This connects the local s3fs bucket mounted volue to the container's '/mapfiles' directory and the EC2's port 8080 to the container's port 80 where Mapserver is exposed. -
sudo docker exec mapserver touch /var/log/ms_error.logto create an error log file. -
sudo docker exec mapserver chown www-data /var/log/ms_error.logto change ownership of the error log file. -
sudo docker exec mapserver chmod 644 /var/log/ms_error.logto change permissions of the error log file. -
Now the docker is running and the log file is setup accordingly. Use
sudo docker exec mapserver cat /var/log/ms_error.logto print the error log file.
This multi-step manual spin up process isn't 100% necessary but it almost is. If you declare the error log file in your mapfiles, mapserver requires it to be there or it simply won't work. Besides, logs are nice.
Alternatively, since we are deploying to ECS, AWS (the ECS agent) will be turning on the Mapserver docker. The ECS agent won't be running the error log file commands after it does so, which means we should create a custom docker image to use in ECS with the error log file already provisioned. We will be running the same basic commands but on your local machine:
-
aws ecr create-repository --repository-name <-- aws account number -->.dkr.ecr.us-east-1.amazonaws.com/custom-mapserverto create an ECR repository for our image. I called it 'custom-mapserver' but you can replace this with whatever name you'd like -
sudo docker run --detach --name mapserver camptocamp/mapserver:7.4to spin up the docker container. -
sudo docker exec mapserver touch /var/log/ms_error.logto create an error log file. -
sudo docker exec mapserver chown www-data /var/log/ms_error.logto change ownership of the error log file. -
sudo docker exec mapserver chmod 644 /var/log/ms_error.logto change permissions of the error log file. -
sudo docker commit mapserver <-- aws account number -->.dkr.ecr.us-east-1.amazonaws.com/custom-mapserverto create an image of the running container tagged as 'latest' -
sudo $(shell aws ecr get-login --region us-east-1 --no-include-email --profile default)to login and get a token for the new ECR repository -
sudo docker push <-- aws account number -->.dkr.ecr.us-east-1.amazonaws.com/custom-mapserverto upload the image
And that's that. The Mapserver docker image has gotten a error log file built into it and is now save in our ECR so that when we deploy an ECS service we can just tell it to use that image.
III - Deploy to ECS
Act III of this story is where we bring together the custom Docker image and deploy it on the custom AMI inside an AWS ECS Cluster. This part will require some background knowledge as the details I can safely provide have a limit. I suggest deploying the services within a single VPC inside limited security groups and communicative subnets which allow these services to work only with each other and only to the extent they need to.
When it comes to managing this infrastructure, I suggest using Terraform. I'm sure there are plenty of other similar products out there, but Terraform is wicked easy and allows one to configure numerous cloud services in coordination with each other and deploy them all simultaneously. This ultimately empowers one to create, alter, and destroy the services super quickly. And if anything happens to them, redeployment is as easy a couple commands from the terminal during a potentially intense time.
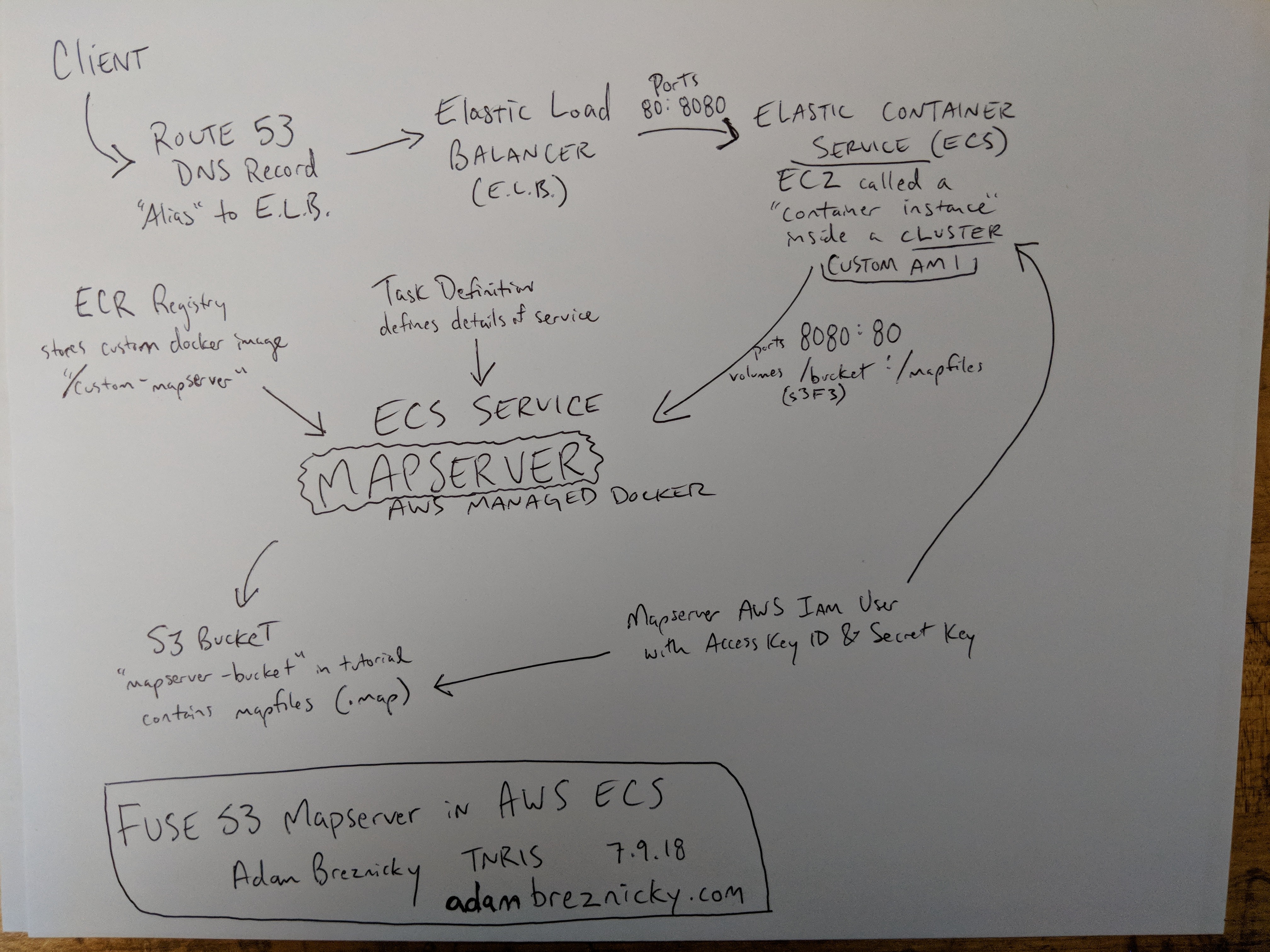
I must take a quick second to apologize in advance for any crisscross terminology confusion. AWS sometimes uses labels with their services which are too literal for their own good. For example, the Cloud Service ECS manages instances of containers (like Docker containers) labelled as 'Services' on 'Container Instances' (which are actually just EC2 servers) --- two different kinds of containers and two different kinds of services. Not what I would have called them but whatever...
- The s3 bucket should already be created because you used it further up the page. Twas a prerequisite afterall!
- The IAM User with a access key and secret key should already be created because you used it further up the page... and will again in the mapfiles.
- Create an ECS cluster with the custom AMI (from above) for it's "Container Instance" (a.k.a. EC2 machine). Terraform allows me to choose any AMI whereas the AWS Console forces you to use the latest greatest ECS optimized one we started with. If you don't want to use Terraform, you'll have to find your own solution for getting your AMI spun up in the cluster.
- Create an Elastic Load Balancer. I use a 'classic' ELB port forwarding all http (80) and https (443) traffic to port 8080 on the "Container Instance". TCP health check port 8080.
- Create a Route 53 DNS record 'ALIAS' to the ELB. This DNS record will be used in the mapfiles (.map) for WMS Service 'online resource' URLs.
- The ECR Registry with the docker image should already be created because you used it further up the page.
-
Create a new EC2 ECS Task Definition.
- Pick any nice task definition name.
- No Task Role or Task Execution Role necessary if networking is done properly.
- Create a volume mapping with a name and the 'Source Path'
/home/ec2-user/bucket. This is the path on your custom AMI to the mapfiles directory (mounted s3fs bucket). We will call this volume mapping mapserver-vol-map - Create the Container Definition. This defines the Mapserver docker instance and for all intents and purposes, is the equivalent to a 'docker run' command. The only crucial parts here are to:
- port map 'Host Port' 8080 from the Container Instance to 'Container Port' 80 on this docker image
- choose the image from the ECR Registered custom docker image
<-- aws account number -->.dkr.ecr.us-east-1.amazonaws.com/custom-mapserver - 'Mount Point' the 'Container Path' volume mapserver-vol-map (you just created this) to 'Source Volume'
/mapfiles
- Within the cluster, you can now 'Create' a new 'Service'. As Launch Type EC2, choose the Task Definiton you just created (should be tagged as 'latest'). Now you can deploy numerous (docker) instances of the Mapserver by choosing the 'Number of Tasks'. The limit is that each instance uses the same 8080 port on it's EC2 host so only one Mapserver docker instance per 'Container Instance' EC2 in the cluser. Go back and up the number of 'Container Instance's in the cluster to up the 'Number of Task' instances.
Aaaaaand that's about it. Drop a mapfile into the s3 bucket, open QGIS, and connect to your service. The URL for the service will depend on the DNS you created in Route 53 and the type of service layer in the mapfile. If your mapfile is a WMS Service, the URL would be something like: http://<-- DNS record -->/wms/?map=/mapfiles/<-- name of mapfile in s3 -->.map
IV - Test
A sample/template WMS Service mapfile can be found in the Just Another COG in the Machine project Github Repo. Here is a direct link but it's way more complex than needed for a simple test. It contains a database hosted tile index layer (in RDS) which connects to individual raster COGs (in s3) served as a separate layer. Simpler, static layer mapfile examples are abound the web if you look.